Model validation
We are going to use another asset check and tie this to our fine_tuned_model asset. This will be slightly more sophisticated than our file validation asset check, since it will need to use both the OpenAI resource and the output of the enriched_graphic_novels asset.
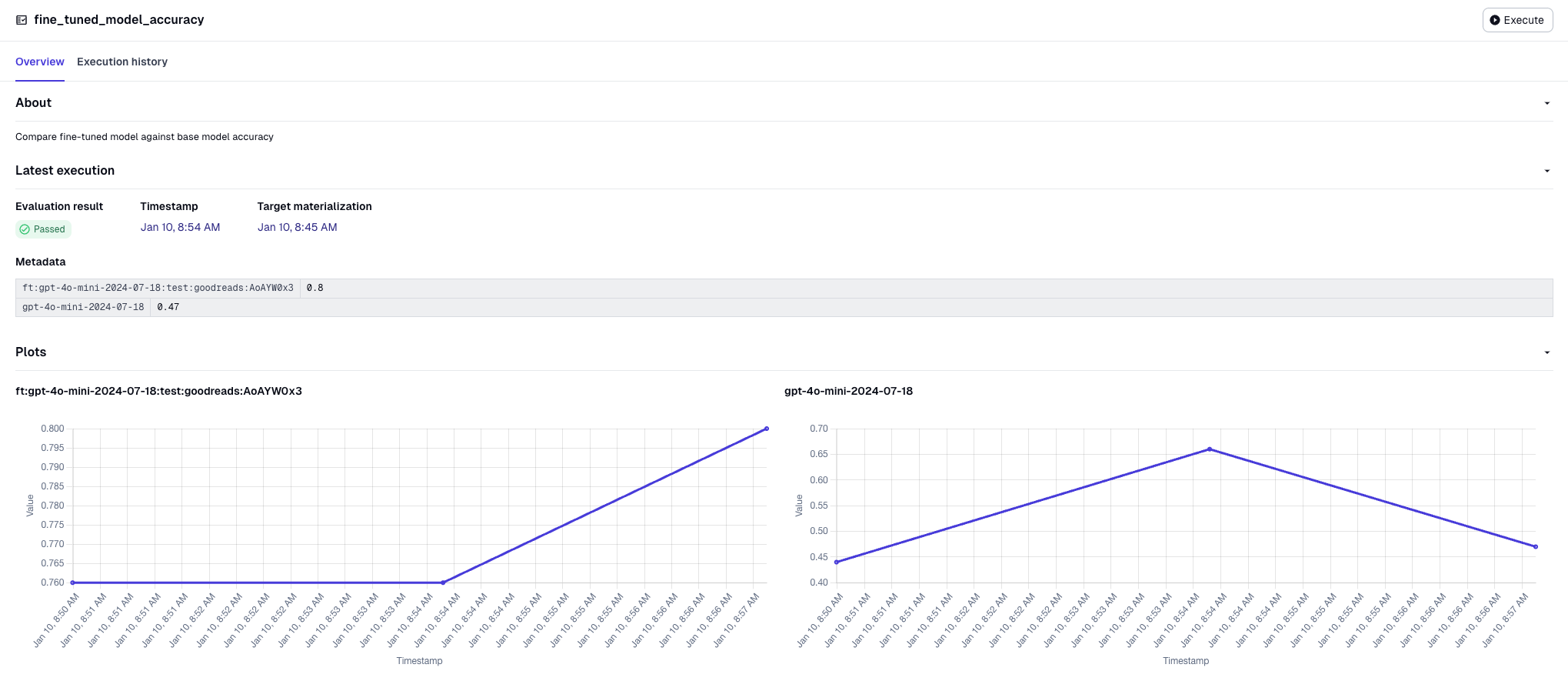
What we will do is take another sample of data (100 records) from our enriched_graphic_novels. Even though our asset check is for the fine_tuned_model model, we can still use the enriched_graphic_novels asset by including it as an additional_ins. Now that we have another sample of data, we can use OpenAI to try and determine the category. We will run the same sample record against the base model (gpt-4o-mini-2024-07-18) and our fine-tuned model (ft:gpt-4o-mini-2024-07-18:test:goodreads:AoAYW0x3). We can then compare the number of correct answers for both models:
@dg.asset_check(
asset=fine_tuned_model,
additional_ins={"data": dg.AssetIn("enriched_graphic_novels")},
description="Compare fine-tuned model against base model accuracy",
)
def fine_tuned_model_accuracy(
context: dg.AssetExecutionContext,
openai: OpenAIResource,
fine_tuned_model,
data,
) -> dg.AssetCheckResult:
validation = data.sample(n=constants.VALIDATION_SAMPLE_SIZE)
models = Counter()
base_model = constants.MODEL_NAME
with openai.get_client(context) as client:
for data in [row for _, row in validation.iterrows()]:
for model in [fine_tuned_model, base_model]:
model_answer = model_question(
client,
model,
data,
categories=constants.CATEGORIES,
)
if model_answer == data["category"]:
models[model] += 1
model_accuracy = {
fine_tuned_model: models[fine_tuned_model] / constants.VALIDATION_SAMPLE_SIZE,
base_model: models[base_model] / constants.VALIDATION_SAMPLE_SIZE,
}
if model_accuracy[fine_tuned_model] < model_accuracy[base_model]:
return dg.AssetCheckResult(
passed=False,
severity=dg.AssetCheckSeverity.WARN,
description=f"{fine_tuned_model} has lower accuracy than {base_model}",
metadata=model_accuracy,
)
else:
return dg.AssetCheckResult(
passed=True,
metadata=model_accuracy,
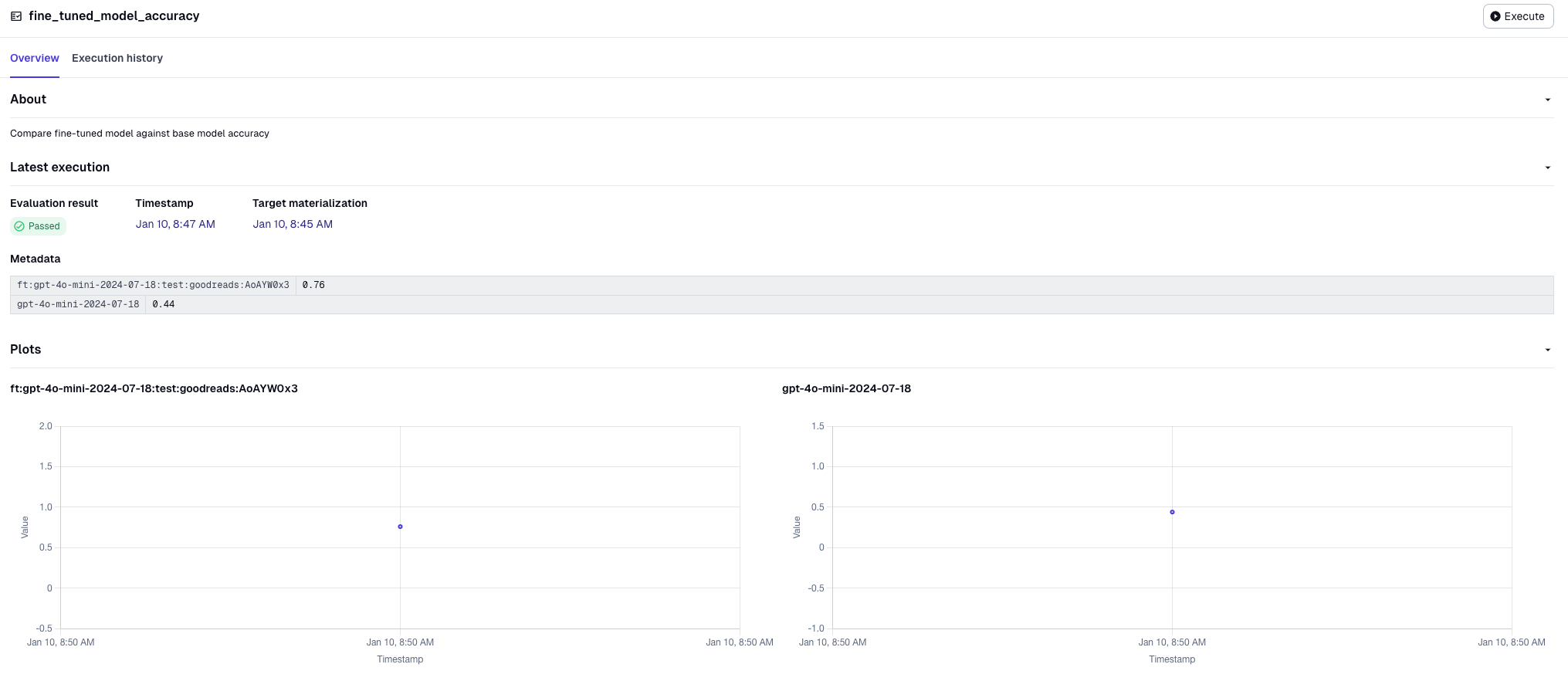
We will store the accuracy of both models as metadata in the check. Because this is an asset check, this will automatically every time we run our fine-tuning asset. When we execute the pipeline, you will see our check has passed since our fine-tuned model correctly identified 76 of the genres in our sample compared to the base model which was only correct in 44 instances.
We can also execute this asset check separately from the fine-tuning job if we ever want to compare the accuracy. Running it a few more times, we can see that the accuracy is plotted: